Algorithms 101 - How to eliminate redundant cache misses in a distributed cache
I'm going to jump right in to a fairly complex subject, for background check out my recent Distributed Cache Webcast here: Online Training.
In the Webcast, I wrote a simple caching service that fronts a simple "GetService" method. I define "GetService" as some service that, for a given key, can retrieve a given value. Pretty basic stuff, if you have ever implemented a SQL query, a Web Service client, or something similar, you can probably envision the implementation. The interface looks like this:
public interface GetService<K, V>
{
public V get(K k);
}
The Typical Solution
Here's where it gets interesting. The common way to implement a cached version of a GetService method would be to perform the following operations:
- Check if K exists in the cache
- If not, load V from the Service (a database for example) using K
- Put (K,V) into the cache
sub get_foo_object {
my $foo_id = int(shift);
my $obj = $::MemCache->get("foo:$foo_id");
return $obj if $obj;
$obj = $::db->selectrow_hashref("SELECT .... FROM foo f, bar b ".
"WHERE ... AND f.fooid=$foo_id");
$::MemCache->set("foo:$foo_id", $obj);
return $obj;
}The problem with this approach is that it simply ignores the race conditions that happens when you have a cache miss. So what, big deal, the gap is really small, right? Ok, fine, if you like races in your code. I don't like races in my code, you shouldn't either. Worse, in the context of a distributed cache, races don't just cause corrupted data, they cause performance degradation.
To solve the race, we have to fix a couple of issues...
Step 1 - Change to First Writer Wins
First, we have to change from a Last Writer Wins to a First Writer Wins strategy.
In the the Last Writer Wins strategy, all of the racing writers put their own version of the value retrieved from the underlying get service into the cache. The last one to do so will end up with their version of the value in the cache. So if there are 10 nodes racing through this code, the underlying service - let's say a database -- will be hit 10 times, and each of the 10 writers will put 10 unique values into the cache (note that the exact value depending on the implementation specifics and timing of changes to the database).
We want to change to a First Writer Wins strategy, so that the cache will return a canonical value regardless of the number of races. To fix to a First Writer Wins, we make one small change to the algorithm. Let's look at the implementation in code:
public final class CachingService<K, V> implements GetService<K, V>
{
...
public V get(K k)
{
V v = cacheStore.getValue(k);
if (v != null) { return v; }
V v = getService.get(k);
return cacheStore.putIfNotExists(k, v);
}
}
In place of Put there is a method called putIfNotExists. This method basically relies on our underlying cache implementation to implement the First Writer Wins strategy. This may be easy or hard, depending on your cache implementation. Lets assume it can be implemented for now.
So, have we solved the problem?
No.
Step 2 - Eliminate redundant reads
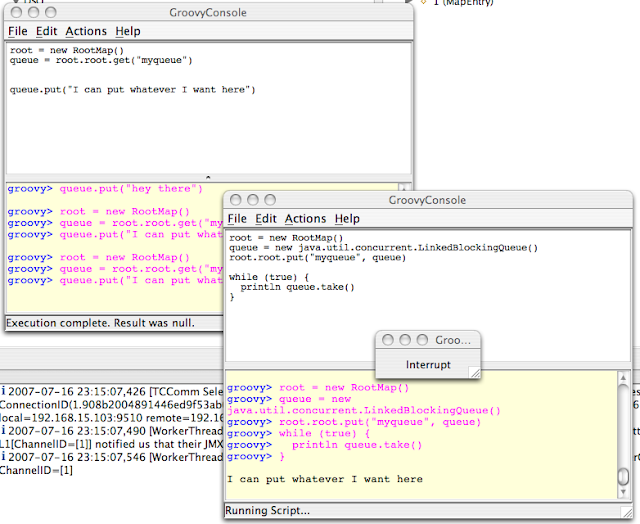
The next thing we have to do is eliminate the multiple reads that happen due to multiple racing writers. This happens in step 2 after each racing writer has discovered that there is a cache miss. What we have to do is coordinate the actions of all of these cache writers so that only one of them goes to the underlying cache service and retrieves the value, puts the value into the cache, and then notifies the other pending writers (now readers) that the value is available.
Sounds easy right? How would you do this? I would think it would be next to impossible in memcached. Maybe your underlying caching technology gives you some locking and messaging APIs - maybe it doesn't. If not there's always RMI, JMS, JGroups, SOAP, ESB, EJB, etc. Sound like fun? Ugggh, not to me.
And how do any of these deal with failures of the node requesting the data? You'll need to let one of other pending readers in after the failure and let it do the read. Correctly handling the entire bevy of problems that happen in a distributed environment is the reason memcached suggests taking the easy way out. It's simply too hard to manage all of the possible failure scenarios.
Don't Give up Just Yet
But wait. That's why Terracotta is such a powerful solution. It doesn't just give you a durable memory store to write to - which of course it does.
In fact, Terracotta extends the entire Java Memory model across the cluster - which means writing code to synchronize and coordinate the actions of many writers is a simple matter of writing natural Java code.
I hope writing natural Java sounds like more fun than using JMS, RMI, proprietary API, and the like. It does to me. If you like writing Java, you'll like writing clustered Java with Terracotta.
So the problem we need to solve is to write some code that can ensure that the value v for some key k is retrieved once and only once. Ensuring mutual exclusion to ensure only one writer reads the value is really trivial if we know we can just rely on Java synchronization - on a single node or many nodes across the cluster which is exactly what we get with Terracotta.
Here's the code:
public class DynamicCacheElement<K, V> implements CacheElement<V>, Serializable
{
...
public synchronized V get()
{
if (v != null) { return v; }
return v = getService.get(k);
}
... (factory methods to follow)
}
That's it - I swear. Note though that in the real code I replace synchronized with a ReentrantReadWriteLock instead of synchronization to optimize the case where the value is not-null allowing more than one reader to enter. Afterall, we want high concurrency in a distributed environment.
All that is left now is to change our CachingService to store CacheElements, not type V, and we are done:
public final CachingService<K, V> implements GetService<K, V>
...
public V get(K k)
{
CacheElement<V> element = cacheStore.getValue(k);
if (element != null) { return element.get(); }
element = elementFactory.createElement(k, getService);
return cacheStore.putIfNotExists(k, element).get();
}
...
}
Summing it up
The new and improved caching service now reads once and only once for a given k, across the cluster using this algorithm:
- Reads the cache for Key k. If the cache contains the value, return the value
- Instantiate a CacheElement which delays the get using the Key k and the underlying GetService until the method get() is called.
- Put the new CacheElement into the cache using a First Writer Wins strategy. Ask the resultant CacheElement to get() the value.
 If you page on over to
If you page on over to  On your buzz page, setup an RSS widget that reads an RSS feed. When users browse your site, the RSS widget reads the RSS feed and gives them the most up to date info. Did you notice the Terracotta Buzz on the right of my
On your buzz page, setup an RSS widget that reads an RSS feed. When users browse your site, the RSS widget reads the RSS feed and gives them the most up to date info. Did you notice the Terracotta Buzz on the right of my  Set up a Yahoo account and create a Yahoo pipe that aggregates RSS feeds from delicious users that are going to generate the buzz for you. Here's the
Set up a Yahoo account and create a Yahoo pipe that aggregates RSS feeds from delicious users that are going to generate the buzz for you. Here's the  After creating the Yahoo Pipe to aggregate del.icio.us links, now all you have to do is populate those links. As the tagger, you want to create a unique set of tags that can be used in the Yahoo! Pipe feed to pull in just the Buzz links. I use the special tag "forterracotta", which you can see by browsing my links here:
After creating the Yahoo Pipe to aggregate del.icio.us links, now all you have to do is populate those links. As the tagger, you want to create a unique set of tags that can be used in the Yahoo! Pipe feed to pull in just the Buzz links. I use the special tag "forterracotta", which you can see by browsing my links here:





